
Introduction
There are many way of using AWS Lambda functions. We found a way that enables us to both leverage global distribution with Cloudfront and the newer, simpler v2 version of API GW. These combined with Lambda result in a fast and secure serverless web application that is simple to deploy and maintain. To take simple infrastructure to another level, we also added Terraform to our toolkit, automating the deployment of the infrastructure.
Why Terraform
Terraform allows engineers to automate cloud infrastructure and configuration, and manage it as code in one place. Managing hundreds of resources on the AWS console can be overwhelming and slow. The UI is inconsistent, and there is no way to have a logical overview of all resources. The situation gets even more complicated if a company uses resources from more than one cloud provider. Terraform provides a consistent view, and all resources are just one click away from each other even if they are from different providers. What can make navigation even easier is the folder structure that companies can plan according to their best practices. Another advantage of Terraform is reusability. Terraform modules are a way to package and reuse configurations. Modules contain multiple resources that are used together allowing resources to be gathered in a logical and practical way.
Implementation
Now, let us go through how we implemented the infrastructure of Depoxy, our ETL management application.
Structuring Code in Terraform
- tf: Folder that contains all Terraform related code
- ci: Folder that contains the CI/CD related resources
- dev: Folder that contains the development stage resources
- api: Folder that contains the api configuration, this is the backend for our app
- www: Folder that contains the www configuration, this is the landing page
- app: Folder that contains the app configuration, this is the JavaScript PWA
- prod: Folder that contains the production stage resources
- api: same as above
- www: same as above
- app: same as above
Each subfolder has its own backend and provider. This means we can deploy changes to stages independently from each other. There cannot be any interference between the stages, and the chance that somebody else is doing changes to that particular environment is minimal. Since the environments are so small, the terraform plan and terraform apply take less than a minute. This allows us to fix issues very quickly and promote changes from dev to prod. The CI folder resources are a bit different than dev or prod becuase CI/CD needs to do different things (like update a Lambda function for example) than the rest of the environments.
Having specific environments gives us the opportunity to apply the least privilige principle. Dev stage can access only dev resources, dev credentials, dev S3 buckets etc.
Modules
Modules (reusable resources) are placed in a different repo, and we reference them using the S3 support of Terraform. Modules can be viewed as templates of a resources with variables that will be assigned a value in the actual API configuration files. Here you can see our three modules for the APIs:
AWS Lambda Module
resource "aws_lambda_function" "lambda-function" {
function_name = "${var.function-name}-function"
description = "${var.function-name}-function"
s3_bucket = var.s3-bucket
s3_key = var.s3-key
source_code_hash = var.source-code-hash
role = var.role-arn
handler = var.handler
layers = var.layers
memory_size = var.memory-size
runtime = var.runtime
timeout = var.timeout
dynamic "environment" {
for_each = length(var.environment-variables) > 0 ? [true] : []
content {
variables = var.environment-variables
}
}
}
Using the AWS Lambda Module
The modules are version controlled and deployed to a S3 bucket using CI/CD. The configuration has two parts: how we would like to have the AWS Lambda function to behave (runtime is Python for example) and how we would like to have the actual Python process to be configured (which SecretId to use for the JWT generation, etc.)
module "lambda-function" {
source = "s3::https://s3-eu-west-1.amazonaws.com/datadeft-tf/modules/lambda/0.0.3/lambda.zip"
role-arn = module.lambda-role.role-arn
s3-bucket = var.lambda-function-s3-bucket-name
s3-key = "api/${var.lambda-function-version}/api.zip"
source-code-hash = chomp(data.aws_s3_object.lambda-function-hash.body)
function-name = replace(var.domain-name, ".", "-")
runtime = "python3.9"
handler = "app.handler"
memory-size = 2048
timeout = 10
layers = var.lambda-layers
environment-variables = {
DEPOXY_API_COOKIE_MAX_AGE_DAYS = "1"
DEPOXY_API_COOKIE_SECURITY = true
DEPOXY_API_CORS_ALLOW_ORIGIN = "https://app.dev.depoxy.dev"
DEPOXY_API_HONEYCOMB_SECRET_ID = "dev/depoxy/api/honeycomb"
DEPOXY_API_JWT_ALGORITHM = "ES256"
DEPOXY_API_JWT_AUDIENCE = "DepoxyDev"
DEPOXY_API_JWT_SECRET_ID = "dev/depoxy/api"
DEPOXY_API_S3_BUCKET = "depoxy-dev"
DEPOXY_API_S3_PREFIX = "api"
DEPOXY_API_SES_SENDER_ADDRESS = "login@send.depoxy.dev"
DEPOXY_API_STAGE = "dev"
}
}
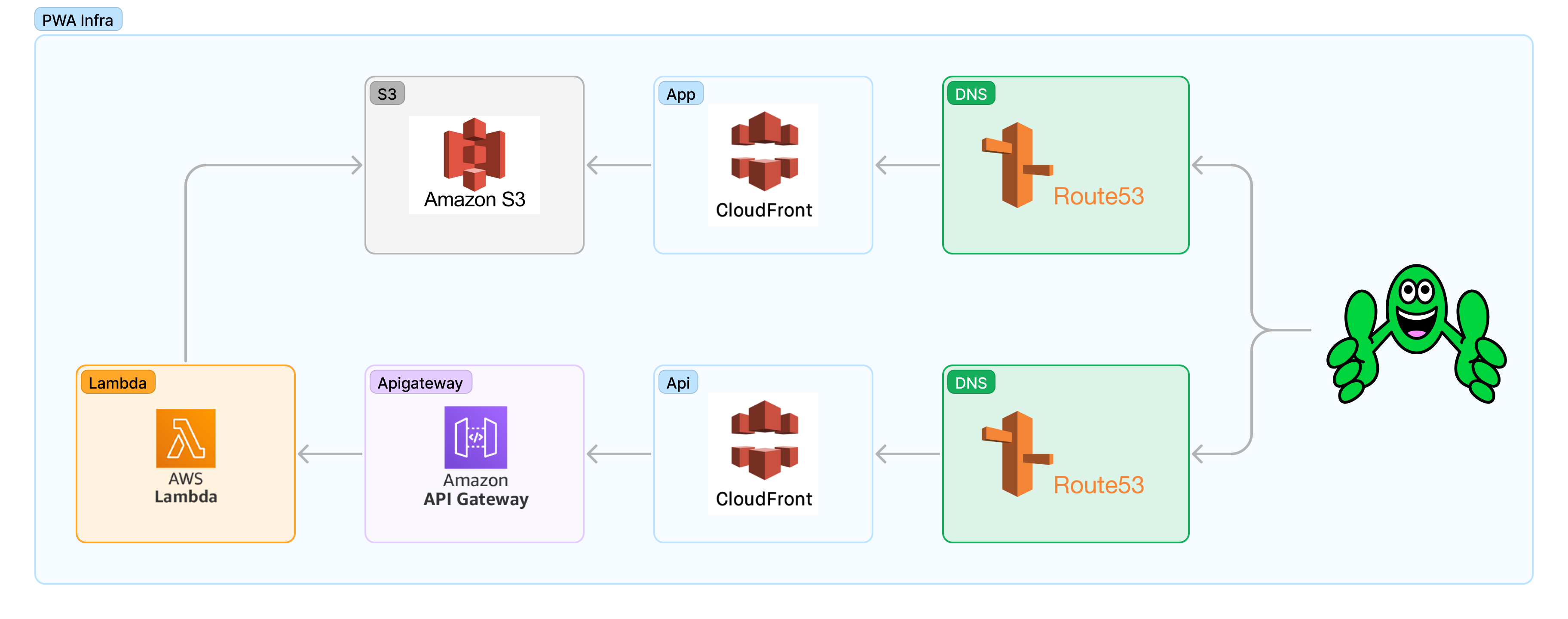
The Complete Picture
We have Terraform as a means to deploy the cloud infrastructure. We need to have the following resources:
- CDN: distributing static files, JavaScript, CSS, HTML, images etc.
- Http load-balancer
- Code execution
- Persistence layer
We leave out data warehousing and ETL for now. That goes to a separate article.
Implementation
We picked the following services:
- CDN: AWS CloudFront
- Http load-balancer: AWS API Gateway (v2)
- Code execution: AWS Lambda
- Persistence: AWS S3
Putting It All Together
I think it is easier to understand how these services are put together when explained in a picture.
Why We Use CloudFront With Lambda Though?
After a bit of a detour into how the infra is deployed, we can tackle the question: why we use Lambda this way. There are few reasons.
First, we need to control where the data is stored because of GDPR and our European customers. We would like to store data in the EU. That means we have a single-region Lambda deployment, which is backed by a single-region data persistence. So we can guraantee that the data never leaves the EU. It is also possible to deploy the stack to a different region when a customer prefers that. Running the Lambda in a single region raises the question of latency for the API calls.
We can mitigate that by putting a CloudFront distribution in the front of Lambda and utilizing all the points of presence AWS has. The request enters AWS’s infra at the earliest possible point and travels through the AWS backbone. It gives us decent latency distributions, which is our second reason to use them together.
We are aware that there are many different ways of using Lambda. AWS introduced new ways recently. However, our current setup prove to be useful for us. Our goal was to create fast and secure applications for our customers at a sustainable price, but we intended not to compromise on “developer-friendliness” either.
Deploying API Gateway with Cloudfront reduces latency around the world and provides security options that API Gateway itself does not offer. The second version also enables authorizers, JWT configuration, CORS headers, and single-source API endpoints with minimal configuration. In addition, AWS Lambda – acting as a serverless backend – handles capacity, scaling, and patching enabling us to focus on development and deliver great user experience.
About Us
We are small consultancy hailing from Europe working on projects mostly in the cloud and data engineering space. If you are interested in talking to us, reach out on hello at datadeft dot eu.